
Recently I have started going raw dog on my databases. I think I love it. Let me explain.
TL;DR; After 25+ years championing ORMs, I’ve switched to raw database queries paired with Python dataclasses. I’m calling it the Raw+DC pattern. The result: better AI coding assistance, fewer aging dependencies, comparable or better performance, and type safety where it counts.
| ORM/ODM | Raw+DC Pattern | |
|---|---|---|
| Type safety | Built-in via entity classes | Dataclasses at the data access boundary |
| AI coding support | Limited by library popularity | Excellent - vanilla query syntax is 1,000x more common |
| Dependency risk | High: ORMs can go unmaintained | Low: only the DB driver |
| Performance | Overhead from serialization/validation | Near-raw speed |
| Query complexity | Abstracted by ORM | Native queries |
What does raw-dogging a database mean?
Rawdog is a slang term that means to endure a difficult, dull, or mundane activity without any diversions or other support while doing it. The word is particularly used in playful or irreverent reference to engaging in ordinary experiences (such as air travel, exercising, or chores) without simultaneously engaging in some form of entertainment (such as listening to music or watching videos). - Merriam-Webster
Why developers use ORMs and ODMs
For almost my entire programming career I have been a massive proponent of the concept of an ORM (relational) and ODM (document) for talking to a database. ORMs provide several key benefits:
- Type-safe entity classes mapped directly to database tables
- SQL injection prevention - no more little bobby tables wrecking your day
- Complex query abstraction - eager joins expressed in Python, not SQL
- IDE autocompletion on every entity field
People would tell me that I’d get better performance if I just did raw db queries that returned tuples or documents. I didn’t care. I still don’t.
But ORMs come with trade-offs (going forward assume ORM and/or ODMs ;) ). You have the entity classes sure. But the ORM usually has some dependencies that can be a hassle. They can be finicky in ways that go beyond what you care about.
How raw database queries work (pymongo example)
There is something lovely about the pure simplicity of a direct query in the native query language of the database. Here’s a pymongo example:
db = get_db(ctx)
doc: dict = db.orders.find_one(
{'order_number': order_number},
{'customer_email': 1, '_id': 0}
)
- Go to the table
orders - Find the one with the order number
order_number - Return only the
customer_email(not even the primary keyid) - Done.
This query is simple, but they can get increasingly complex. ORMs seriously help for complex queries (think multiple eager joins!) Maybe you don’t want to write those complex queries. I sure don’t and didn’t see the benefit of doing so except in a very narrow high-traffic use-cases.
Another benefit of ORMs is that your IDEs and type checkers can tell you exactly where an ORM class is being used since every query is expressed in terms of one or more of these classes.
Why AI coding assistants work better with raw queries
You see, I have this friend named Claude. He’s really good at programming. Gets distracted, but if kept on track he can nail a three-way eager join in SQL.
Seriously now. After a significant amount of experience programming ORM-backed projects with Claude Opus/Sonnet, it dawned on me that I’m writing fewer of the queries by hand and just telling Claude what to do. And we have to keep in mind one of the key rules of working with agentic coding:
My universal 7th rule of agentic coding: AI coding works best for extremely popular languages, tools, and platforms. Given a specialized tool or framework vs. a general “vanilla” one, choose vanilla if everything else is equal.
Claude knows the Beanie ODM great (which I use for some of my apps). But do you know what it knows better? Pure, native MongoDB query syntax. Vanilla.
Look at these stats:
- Beanie: 1.4M downloads/month PyPI Stats
- PyMongo: 74.2M downloads/month PyPI Stats
PyMongo is 53x times more popular. The syntax it needs is actually identical across the Node/Deno/Bun ecosystem, the PHP ecosystem, and many others. This makes the examples of pymongo (aka native MongoDB) queries likely 1,000x more common. Agentic AI will likely do much better with this query foundation.
How to keep type safety without an ORM
Remember my adoration of the type safety and the IDE support? Coding with classes returned from the DB queries is unquestionably better in most cases. You specify the return type (db class), get a return value named result, type result. and boom, a list of fields appears before your eyes. This also works for powering ty, pyrefly, and all the other type checkers.
My realization is that we don’t actually need the types baked entirely into the queries. I just want to talk in Python classes beyond the data access layer.
Enter dataclasses.
If we just make the data access layer convert results to data classes when it’s to our benefit and keep them as single values (scalars) for basic queries, we get almost all the benefits of a full ORM without many of the drawbacks. This is the core of the Raw+DC pattern (aka raw dog 🐶).
Here’s an example from MongoDB/pymongo. Notice the embedded data classes Address, Payment, StatusEntry, and LineItem.
@dataclass(slots=True)
class Order:
id: ObjectId
order_number: str
customer_email: str
status: str
total_cents: int
item_count: int
created_at: datetime
updated_at: datetime
shipping_address: Address
payment: Payment
line_items: list[LineItem]
status_history: list[StatusEntry]
We just write a to/from dictionary method to handle the top-level classes and we have a much lighter weight data access layer.
def order_from_doc(doc: dict) -> Order:
return Order(
id=doc['_id'],
order_number=doc['order_number'],
customer_email=doc['customer_email'],
status=doc['status'],
total_cents=doc['total_cents'],
item_count=doc['item_count'],
created_at=doc['created_at'],
updated_at=doc['updated_at'],
shipping_address=Address(**doc['shipping_address']),
payment=Payment(**doc['payment']),
line_items=[LineItem(**li) for li in doc['line_items']],
status_history=[StatusEntry(**sh) for sh in doc['status_history']],
)
I can already hear the critics: “You’ve just built a worse ORM by hand!” Fair point. But this thin conversion layer is exactly the kind of boilerplate that AI coding assistants excel at generating and maintaining. When your dataclass changes, Claude can update order_from_doc in seconds. It’s fully transparent (no framework magic to debug), has zero dependencies beyond the standard library, and you own every line of it.
Now, before you close your browser in disgust, let me share two bits of data:
- Why ORMs go unmaintained (and raw queries don’t)
- Performance benchmarks
Why ORMs go unmaintained (and raw queries don’t)
This one makes me sad. But I’ve been doing Python and working with amazing packages from PyPI long enough to see it over and over.
Some of these ORMs just start to fade into obscurity due to neglect.
My beloved Beanie ODM has only had a few releases in 2025. Latest release: 4 months ago. Open issues: 91. Pending PRs: 18 (one of which is for a bug I’ve been chasing for years now).
Before Beanie, I was using mongoengine. Some of my major apps still run on mongoengine. But it hasn’t seen a release in years. It never got updated to async. Sad face.
Working closer to the DB means you only really go into unmaintained mode if the DB itself does. For example, pymongo had a release just a few weeks ago. Plus, we can always move the raw queries to another library like motor if needed.
Raw queries vs ORM performance: dataclasses + pymongo benchmarks
The Raw+DC pattern is as fast as pure raw queries and significantly faster than ORMs for large datasets. No one would question whether just running dictionaries in/out in raw queries would be faster than doing full entity class serialization and validation on top of that same layer.
But what actually is the cost of my recommended frankenstein raw queries + data classes? Is it actually worse than the ORMs?
Spoiler: low and not at all.
Check out the graph (click to zoom). Data classes + raw = purple, orange = Beanie, green = mongoengine. The - - - - blue line is pure pymongo.
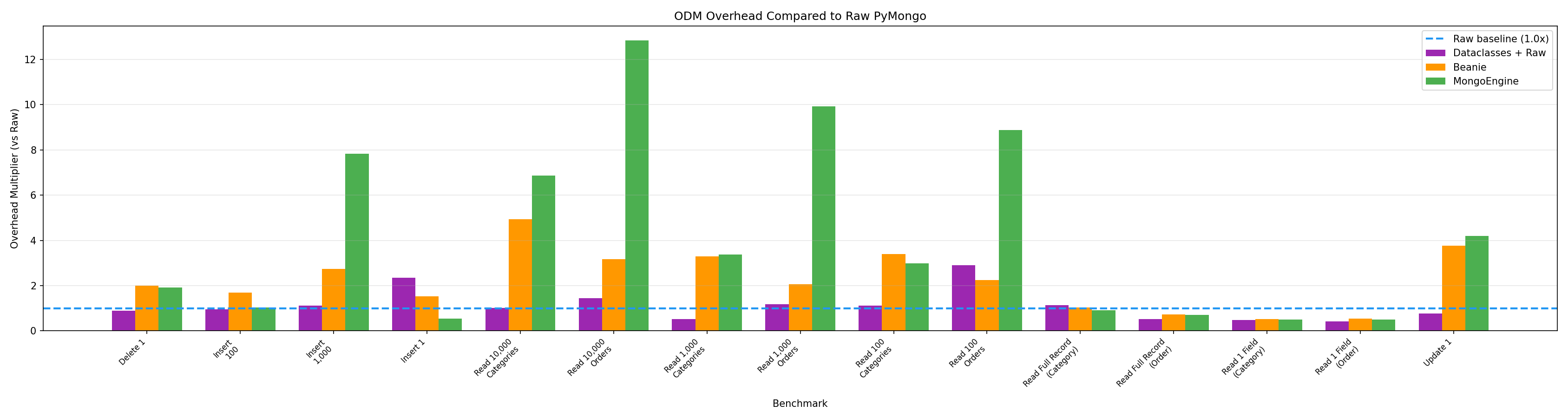
You can see any time you’re working with large amounts of data, raw dog is actually much faster. Beanie represents well all things considered. MongoEngine is seriously showing its age.
Performance comparisons are always fraught with pitfalls. But you get a sense of things from the picture nonetheless. You can explore all of this code and run it for yourself. Check out the GitHub repo at:
ORM vs Raw MongoDB Benchmarks: github.com/mikeckennedy/orm-vs-raw-mongo
You’ll need MongoDB running. Just run this docker command then you can run the demos:
docker pull mongo:latest && docker run -d --rm -p 0.0.0.0:27017:27017 --name mongosvr mongo:latest
Then run this in the main repo:
uv sync
uv run main.py run
Should you switch from an ORM to raw queries?
Here’s my final case for the Raw+DC pattern, letting Claude (or you) write raw queries, adapted to light-weight dataclasses at the data access layer.
- Your query library and code is much less likely to go out of support
- It’s very fast
- You still get typed support anywhere you are writing code
- You have fewer (often many fewer) dependencies
So are you going to go raw dog? Give it a try and see what you think.
Just be careful to always use safe query practices when using user input. That means parameterized queries for SQL and always convert user input to strings (not dictionaries) in MongoDB.
Frequently asked questions about ditching your ORM
Is it safe to use raw database queries instead of an ORM?
Yes, as long as you follow safe query practices. For SQL, always use parameterized queries, never string concatenation. For MongoDB, always convert user input to strings (not dictionaries) to prevent query injection. The ORM’s safety comes from parameterization, and you can do that yourself.
Are raw database queries faster than ORMs in Python?
Yes. Raw queries with dataclasses (the Raw+DC pattern) perform nearly identically to pure raw dictionary queries and significantly outperform ORMs like Beanie and mongoengine on large datasets. The dataclass conversion overhead is minimal compared to full ORM entity serialization and validation.
How do you get type safety without an ORM?
Use Python dataclasses (or Pydantic models) as your entity types. Write a thin conversion layer, to_dict() and from_doc() methods, at the data access boundary. Beyond that boundary, all your application code works with fully typed classes, giving you IDE autocompletion and type checker support.
Do AI coding assistants work better with raw queries or ORMs?
AI assistants like Claude work dramatically better with raw/native query syntax. PyMongo has 53x the downloads of Beanie, and native MongoDB query syntax is shared across Node.js, PHP, and other ecosystems, making training examples 1,000 of times more common. More training data means more accurate, reliable code generation.